
Yilong Li
I am a PhD in Computer Science at the University of Wisconsin-Madison, advised by Professor Suman Banerjee. My research interests span networked and wireless systems, efficient on-device inference for large language models (LLMs), and mobile & wearable devices. With extensive experience in hardware design and wireless system, I explore the way of building systems in a software-hardware co-design approach. Recently, I’ve been working on efficient LLM inference for small, battery-powered edge devices, using a software-hardware co-design approach. This includes customized frameworks for deploying multi-modal models (Llama-3, LLaVa) with various quantization methods. I've also optimized llama.cpp on Mali GPU hardware, integrating OpenCL (CLBlast) and OpenBLAS to improve performance and power management.
- Networked/Wireless System: Wireless systems, especially wireless sensing system for human vital sign. mmWave integrated sensing and communication (ISAC); Ultra-Wide Band (UWB) Sensing System. Build both hardware and software for wireless sensing systems, especially for sensing systems that include human vital signs and gestures. Extensive experience in RF, microwave design, and PCB design.
- Efficient LLM On-device Inference for LLM: Developing efficient LLM inference for small, battery-powered edge devices, using frameworks in a software-hardware co-design approach with customized cpp implemented framework, enabling cost-effective deployment of large multi-modal models (Llama-3, LLaVa, Qwen) with various quantization methods (GPTQ, AWQ, 1-bit).
- Multimodal LLMs for wearable devices and sensor data: Recently my interest is to explore multi-modilities (sensor data, camera) for mobile and wearable devices, enabling real-time, on-device assistance for visual and language tasks. I also designed a wearable earphone hardware with our tiny LLM system, incorporating IMU sensors and cameras to support visually impaired and elderly users in locating objects and identifying road signs during navigation, in neural language.
I also spent total one year at NEC Laboratories America as a Research Intern from 2020 to 2021. During this time, I developed a scalable, high-resolution 16×16 Ultra-Wideband (UWB) radar system from hardware design, firmware to algorithm, for monitoring human vital signs, such as respiration and heart rate. The system conduct a hardware-algorithm co-design that a multi-head attention contrastive learning model to process the data from each of the antenna arrays for accurately extract these signals from multiple moving targets in complex indoor environments. This significant effort takes me two years to build a comprehensive hardware platform and was an incredibly engaging experience.
My research interests have recently evolved towards developing efficient inference AI systems on wearable and edge devices through a software-hardware co-design approach. I now focus on creating inference-efficient hardware for deploying multimodal LLMs on mobile and wearable devices, with applications in areas such as healthcare, including vital sign sensing. To support this, I designed a customized C++ framework that efficiently offloads model layers to NPUs and GPUs, enabling small devices to run large models with exceptional speed and efficiency.
Email / GitHub / Google Scholar / LinkedIn
Work in Progress

1. NeuralGuide – Bridging multimodal intelligence and wearable accessibility with on-device LLMs.
A wearable earpiece device with camera and IMU sensor powered by our TinyLLM hardware platform performs fully on-device, multimodal inference without requiring internet connectivity. Equipped with an integrated camera, the device runs a visual instruction model (LlaVa-Onevision) to assist visually impaired individuals or elderly users in locating objects or navigating environments, such as identifying road signs or nearby landmarks. By leveraging a software-hardware co-design, the system ensures real-time, local natural language interaction. Current challenges include enhancing the device's positioning and reasoning capabilities to improve accuracy and reliability, addressing limitations in object localization and context understanding.
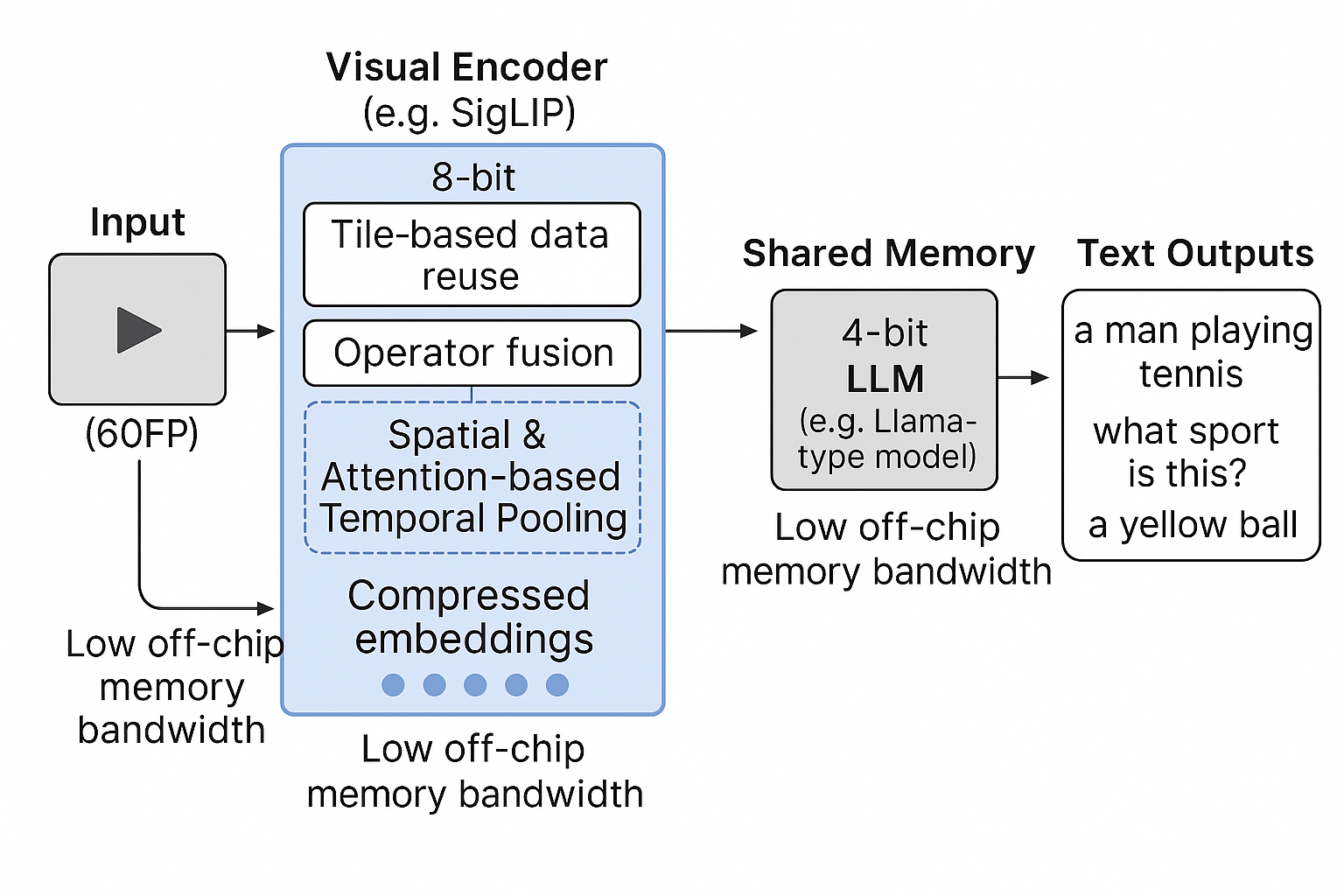
2. Split to Fit: Cross-Accelerator Hybrid Quantization for Efficient Video Understanding on Edge Systems.
We present a system for efficient vision-language model (VLM) inference on mobile SoCs with unified memory, exemplified by deployment on RK3588. Our design decouples VLM execution across heterogeneous accelerators: an 8-bit vision encoder runs on the NPU, while a 4-bit language model runs on the GPU. These modules communicate via shared DRAM buffers, avoiding PCIe overhead.To reduce token and compute load, we introduce two lightweight modules: Spatial Embedding Reduction, which compresses ViT outputs without modifying the encoder, and Temporal Attention Pooling, which fuses multi-frame embeddings to preserve temporal information at reduced frame rates. Together, these enable high-throughput inference from 60fps input to 15ps language output under tight memory and power constraints. Our implementation on RK3588 achieves efficient, real-time VLM inference within sub-1GB memory, offering a practical solution for deploying multimodal intelligence at the edge.
Selected Publications
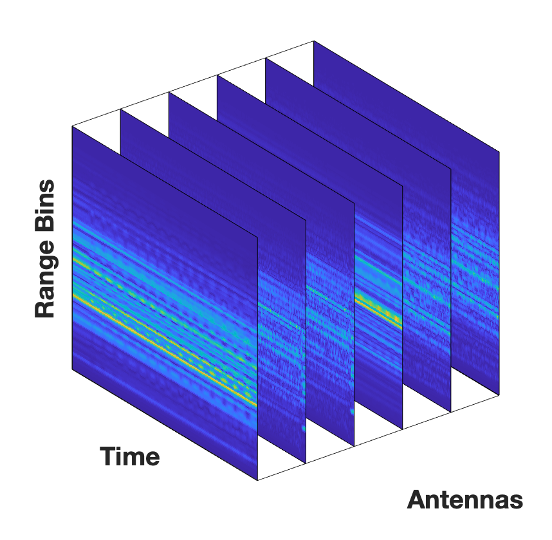
1. Medusa: Scalable Multi-View Biometric Sensing in the Wild with Distributed MIMO Radars
Yilong Li, Ramanujan K Sheshadri, Karthik Sundaresan, Eugene Chai, Yijing Zeng, Jayaram Raghuram, Suman Banerjee
MobiCom 2025
2025
arxiv /
pdf /
link /
bib
/
abstract
/
@misc{li2024medusascalablebiometricsensing,
title={MEDUSA: Scalable Biometric Sensing in the Wild through Distributed MIMO Radars},
author={Yilong Li and Ramanujan K Sheshadri and Karthik Sundaresan and Eugene Chai and Suman Banerjee},
year={2024},
eprint={2310.05507},
archivePrefix={arXiv},
primaryClass={cs.AR},
url={https://arxiv.org/abs/2310.05507},
}Radar-based techniques for detecting vital signs have shown promise for continuous contactless vital sign sensing and healthcare applications. However, real-world indoor environments face significant challenges for existing vital sign monitoring systems. These include signal blockage in non-line-of-sight (NLOS) situations, movement of human subjects, and alterations in location and orientation. Additionally, these existing systems failed to address the challenge of tracking multiple targets simultaneously. To overcome these challenges, we present MEDUSA, a novel coherent ultra-wideband (UWB) based distributed multiple-input multiple-output (MIMO) radar system, especially it allows users to customize and disperse the 16×16 into sub-arrays. MEDUSA takes advantage of the diversity benefits of distributed yet wirelessly synchronized MIMO arrays to enable robust vital sign monitoring in real-world and daily living environments where human targets are moving and surrounded by obstacles. We've developed a scalable, self-supervised contrastive learning model which integrates seamlessly with our hardware platform. Each attention weight within the model corresponds to a specific antenna pair of Tx and Rx. The model proficiently recovers accurate vital sign waveforms by decomposing and correlating the mixed received signals, including comprising human motion, mobility, noise, and vital signs. Through extensive evaluations involving 21 participants and over 200 hours of collected data (3.75 TB in total, with 1.89 TB for static subjects and 1.86 TB for moving subjects), MEDUSA's performance has been validated, showing an average gain of 20% compared to existing systems employing COTS radar sensors. This demonstrates MEDUSA's spatial diversity gain for real-world vital sign monitoring, encompassing target and environmental dynamics in familiar and unfamiliar indoor environments.

2. PRISM: Portable Resource-efficient Inference System for Multimodal Models on a Tiny Device
Yilong Li, Shuai Zhang, Hao Zhang, Jingyu Liu, Pan Hu, Jayaram Raghuram, Suman Banerjee
Under Review
2024
arxiv /
pdf /
poster /
link /
abstract
/
Large Multimodal Models (LMMs) have revolutionized various tasks. However, deploying them on resource-constrained devices poses significant challenges due to limit computational power and battery life. Existing frameworks struggle with poor performance and lack of GPU support on mobile and small embedded devices, often neglecting considerations for battery efficiency. To solve these challenges, we present the first attempt to explore the full potential of low-cost and tiny hardware in a software-hardware co-design approach that enables efficient on-device inference of large multimodal models (LMMs) on resource-constrained devices, supporting modalities~(voice, vision). By utilizing multiple optimizations across hardware, software, and models, the system maximizes the efficiency on extremely resource-limited devices. We made substantial efforts in hardware design, system-level implementation, and model compression, particularly the optimization of mobile GPU drivers for low-bit quantized models. We've also developed a power-efficient workload offloading mechanism that dynamically allocates computations to the GPU or NPU based on resource usage and power consumption. By employing these efforts, a tiny device can efficiently operate large language models ~(LLMs) and models with modalities) within constrained hardware resources by directly offloading workloads to on-device GPU or NPU based on power and memory usage, bypassing CPU RAM. This approach enhances inference performance and significantly reduces power consumption. Our efforts explored the limitations of constrained resources through optimized hardware integration and innovative workload scheduling, supporting multi-modal interactions like language, voice, and sensor data processing—all within a single unit. Our device operates independently on minimal power for extended periods, maintaining high energy efficiency and privacy by processing data locally without needing internet connectivity. Running LLMs locally on a compact device not only enhances data security and privacy, our effort of such a tiny device represents a major step forward in making sophisticated multi-modal inference accessible on the smallest and most energy-efficient platforms.
3. PalmBench: A Comprehensive Benchmark of Compressed Large Language Models on Mobile Platforms
Yilong Li, Jingyu Liu, Hao Zhang, M Badri Narayanan, Utkarsh Sharma, Shuai Zhang, Pan Hu, Yijing Zeng, Bangya Liu, Jayaram Raghuram, Suman Banerjee
ICLR 2025
2024
arxiv /
pdf /
link /
bib
/
abstract
/
@misc{li2024palmbenchcomprehensivebenchmarkcompressed,
title={PalmBench: A Comprehensive Benchmark of Compressed Large Language Models on Mobile Platforms},
author={
Yilong Li and Jingyu Liu and Hao Zhang and
M Badri Narayanan and Utkarsh Sharma and
Shuai Zhang and Pan Hu and Yijing Zeng and
Jayaram Raghuram and Suman Banerjee
},
year={2024},
eprint={2410.05315},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2410.05315},
}Deploying large language models (LLMs) locally on mobile devices is advantageous in scenarios where transmitting data to remote cloud servers is either undesirable due to privacy concerns or impractical due to network connectivity. Recent advancements have facilitated the local deployment of LLMs. However, local deployment also presents challenges, particularly in balancing the (generative) quality, latency, and throughput within the hardware constraints of mobile devices. In this paper, we introduce our lightweight, all-in-one automated benchmarking framework that allows users to evaluate LLMs on mobile devices. We provide a comprehensive benchmark of various popular LLMs with different quantization configurations (both weights and activations), across multiple mobile platforms with varying hardware capabilities. Unlike traditional benchmarks that assess full-scale models on high-end GPU clusters, we focus on evaluating resource efficiency (memory and power consumption) and harmful output for compressed models on mobile devices. Our key observations include: i) differences in energy efficiency and throughput across mobile platforms; ii) the impact of quantization on memory usage, GPU execution time, and power consumption; iii) accuracy and performance degradation of quantized models compared to their non-quantized counterparts; and iv) the frequency of hallucinations and toxic content generated by compressed LLMs on mobile devices.
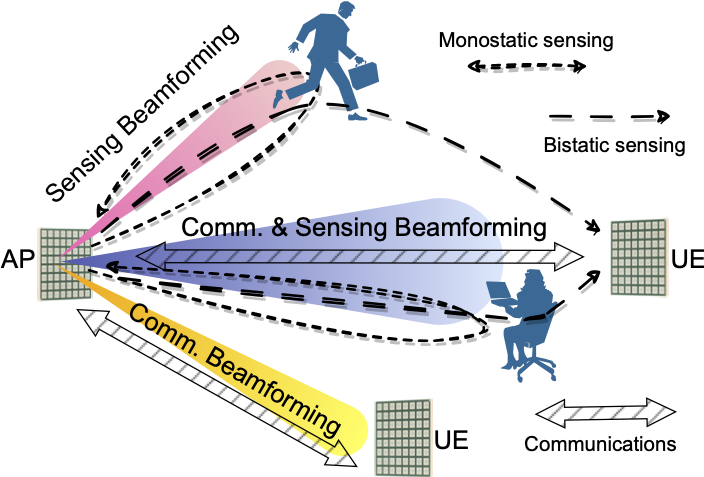
4. Gemini: Integrating Full-fledged Sensing upon Millimeter Wave Communications
Yilong Li, Zhe Chen, Jun Luo, Suman Banerjee
Under Review
2023
arxiv /
pdf /
link /
bib
/
abstract
/
@misc{li2024geminiintegratingfullfledgedsensing,
title={Gemini: Integrating Full-fledged Sensing upon Millimeter Wave Communications},
author={Yilong Li and Zhe Chen and Jun Luo and Suman Banerjee},
year={2024},
eprint={2407.04174},
archivePrefix={arXiv},
primaryClass={cs.NI},
url={https://arxiv.org/abs/2407.04174},
}Integrating millimeter wave (mmWave)technology in both communication and sensing is promising as it enables the reuse of existing spectrum and infrastructure without draining resources. Most existing systems piggyback sensing onto conventional communication modes without fully exploiting the potential of integrated sensing and communication (ISAC) in mmWave radios (not full-fledged). In this paper, we design and implement a full-fledged mmWave ISAC system Gemini; it delivers raw channel states to serve a broad category of sensing applications. We first propose the mmWave self-interference cancellation approach to extract the weak reflected signals for near-field sensing purposes. Then, we develop a joint optimization scheduling framework that can be utilized in accurate radar sensing while maximizing the communication throughput. Finally, we design a united fusion sensing algorithm to offer a better sensing performance via combining monostatic and bistatic modes. We evaluate our system in extensive experiments to demonstrate Gemini's capability of simultaneously operating sensing and communication, enabling mmWave ISAC to perform better than the commercial off-the-shelf mmWave radar for 5G cellular networks.

5. Enabling Wideband, Mobile Spectrum Sensing through Onboard Heterogeneous Computing
Yilong Li, Yijing Zeng, Suman Banerjee
HotMobile 2021
2021
arxiv /
pdf /
link /
bib
/
abstract
/
@inproceedings{10.1145/3446382.3448651,
author = {Li, Yilong and Zeng, Yijing and Banerjee, Suman},
title = {Enabling Wideband, Mobile Spectrum Sensing through Onboard Heterogeneous Computing},
year = {2021},
isbn = {9781450383233},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3446382.3448651},
doi = {10.1145/3446382.3448651},
booktitle = {Proceedings of the 22nd International Workshop on Mobile Computing Systems and Applications},
pages = {85–91},
numpages = {7},
keywords = {Mobile spectrum sensing, Heterogeneous computing},
location = {Virtual, United Kingdom},
series = {HotMobile '21}
}We explore the design of a platform to support truly mobile and untethered, wideband spectrum sensing. First, the design of the platform needs to be physically small and lightweight. Next, we observe that wideband spectrum sensing (say > 20 MHz at a time) can easily generate a large volume of PSD/IQ data, in uncompressed form (> 1 Gbps). Due to challenges of efficient offload of this large data volume, we design a heterogeneous computing platform — using a combination of FPGA and CPU — built right on the spectrum sensor board, onto which various sophisticated compression algorithms, or wireless signal processing functions (even deep learning based ones) can be implemented. The FPGA is chosen to meet the real-time processing requirements of modern high-speed wireless protocols, opening new opportunities. Finally, we provide easy connectivity to common mobile devices (currently Android phone) and a starting mobile app to enable easy programmability and control functions. Overall, our highly-integrated platform has the capability of sensing a wide frequency range of wireless signals with a high sampling rate and being controlled by a mobile phone via a USB OTG cable. We build a prototype of our system and show through experiments that our device can support a bandwidth up to 56 MHz and a wide frequency range from 70 MHz to 6 GHz for spectrum sensing, and run a deep learning model inference onboard for signal classification. We conclude by discussing the future challenges to realize large-scale spectrum sensing using our platform.
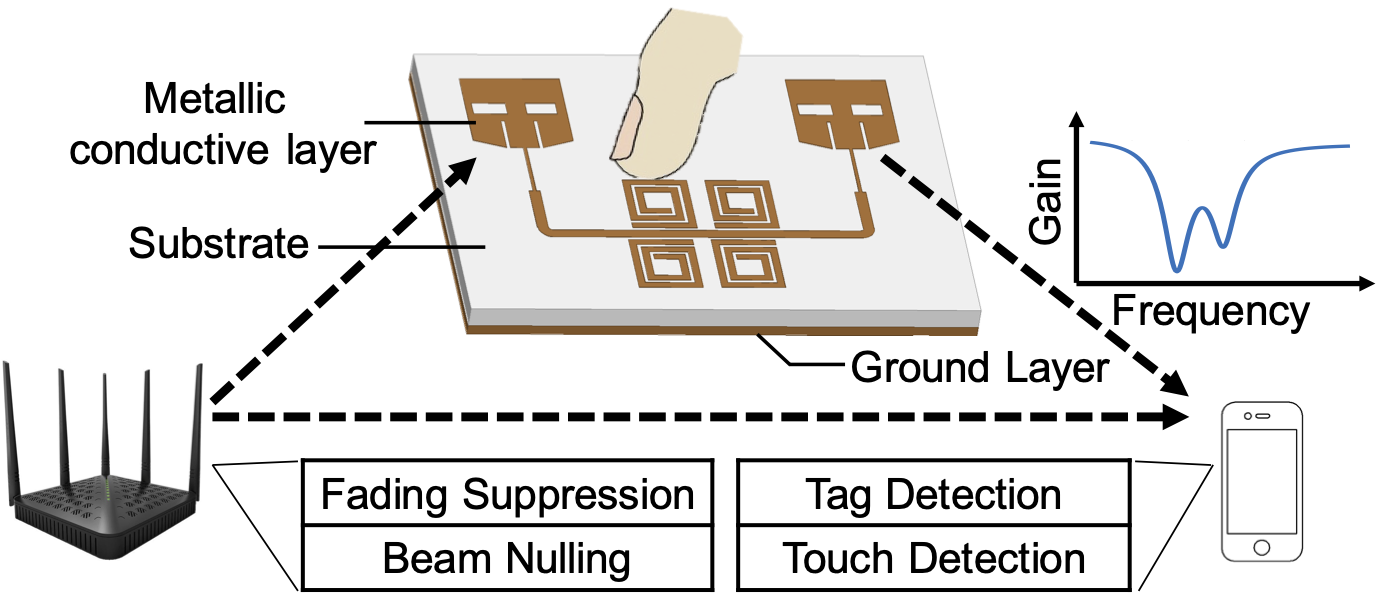
6. LiveTag: Sensing Human-Object Interaction through Passive Chipless WiFi Tags
Chuhan Gao and Yilong Li, Xinyu Zhang
NSDI 2018
2018
pdf /
link /
bib
/
abstract
/
@inproceedings{livetag_NSDI2018,
author = {Gao, Chuhan and Li, Yilong and Zhang, Xinyu},
title = {Livetag: sensing human-object interaction through passive chipless WiFi tags},
year = {2018},
isbn = {9781931971430},
publisher = {USENIX Association},
address = {USA},
booktitle = {Proceedings of the 15th USENIX Conference on Networked Systems Design and Implementation (NSDI 2018)},
pages = {533–546},
numpages = {14},
location = {Renton, WA, USA},
series = {NSDI'18}
}Many types of human activities involve interaction with passive objects. Thus, by wirelessly sensing human interaction with them, one can infer activities at a fine resolution, enabling a new wave of ubiquitous computing applications. In this paper, we propose LiveTag to achieve this vision. LiveTag is a fully passive, thin metal tag that can be printed on paper-like substrates and attached to objects. It has no batteries, silicon chips, or discrete electronic components. But when touched by fingers, it disturbs the ambient WiFi channel in a deterministic way. Multiple metallic structures can be printed on the same tag to create unique touch points. Further, LiveTag incorporates customized multi-antenna beamforming algorithms that allow WiFi receivers to sense the tag and discriminate the touch events amid multipath reflections/interferences. Our prototypes of LiveTag have verified its feasibility and performance. We have further applied LiveTag to real-world usage scenarios to showcase its effectiveness in sensing human-object interaction.
Design and source code modified from Jon Barron's website. Edit here.